|
|
|
|
|
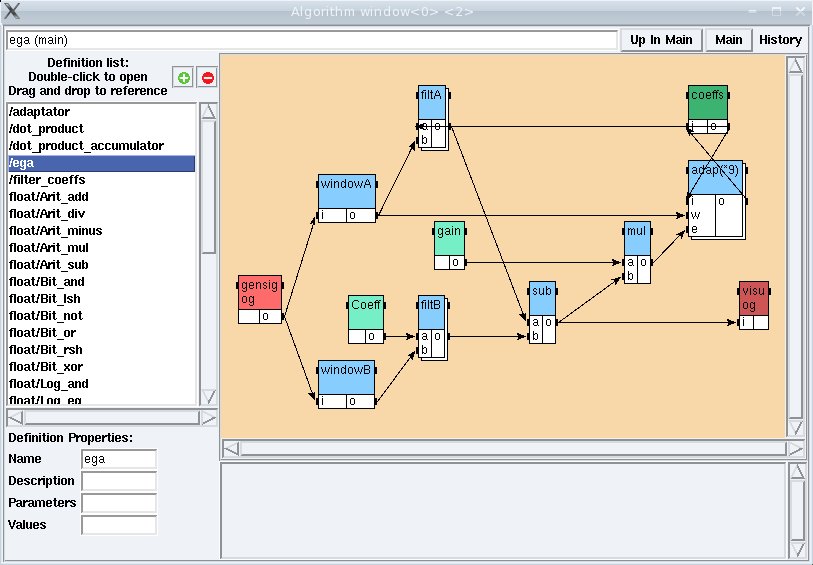
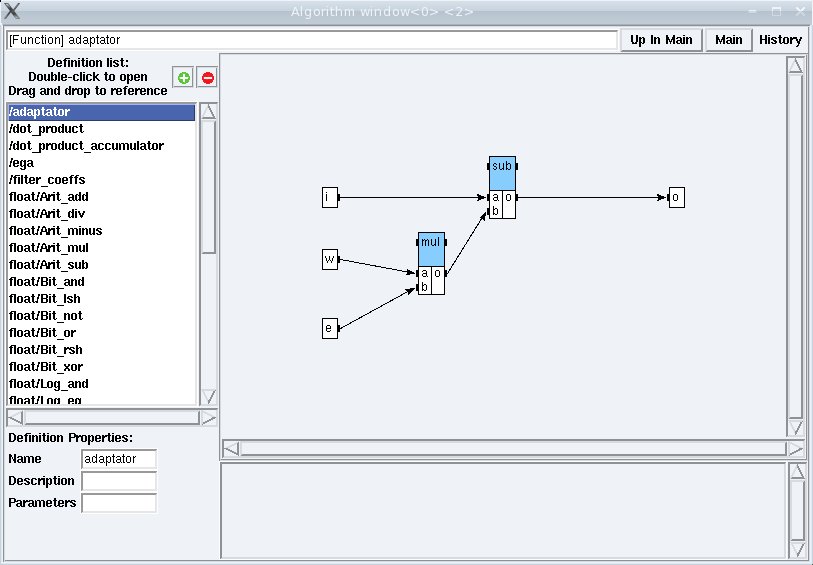
This simple example shows the graphical user interface of SynDEx for the implementation of the algorithm ega onto the architecture archi2procs. The window ega (main) shows the algorithm graph, here a typical identification filter (filt) based on an adaptive filter (filta) whose coefficients are calculated with an algorithm using a stochastic gradient that we called adaptator. The vertices with double border filt, filta, and adap contain hierarchy, i.e. they are in turn described as graphs. The window [Function] adaptator shows the graph obtained when clicking on the vertex adap. Red vertices represent sensors and actuators. Dark-green vertices represent delays. Light-green vertices represent constants. Blue vertices represent operations. Only these latter types of vertices can be hierarchical. To each leaf vertex (without hierarchy), is associated an executable code (C, assembly languages, VHDL, etc...) which will be used by the automatic code generator of SynDEx. Executable codes are stored in SynDEx's librairies or given by the user. The edges are dependences between the output of a vertex and the input of one, or possibly, several (diffusion) other vertices.
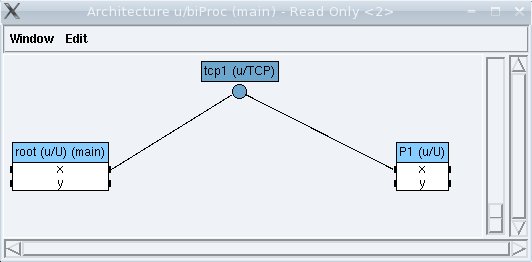
The window Architecture u/biProc (main) shows the architecture graph, composed of two processors P0 and P1, interconnected by a communication medium of type TCP/IP. Light-blue vertices represent processors. Dark-blue vertices represent communication media. Edges represent connections between a processor and a medium.
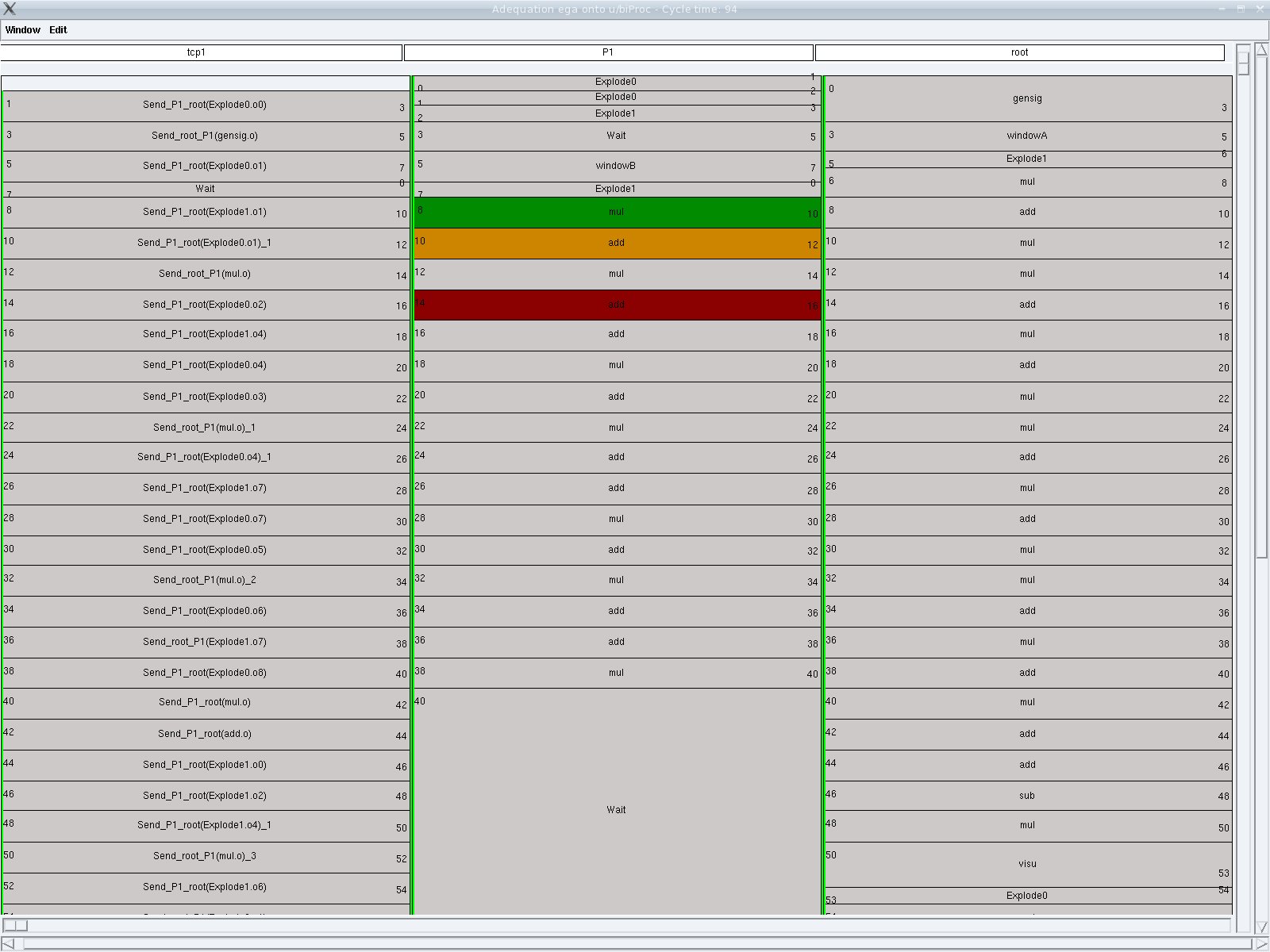
The window Adequation ega onto u/biProc shows the result of the adequation applied to the algorithm and the architecture labelled (main). This is a timing window describing how the algorithm is distributed and scheduled onto the architecture by the optimization heuristics of SynDEx. It includes one column for each processor and communication medium, describing the distribution (spatial allocation) and the scheduling (temporal allocation) of operations on processors, and of inter-processor data transfers on communication media. Here time flows from top to bottom, the height of each box is proportional to the execution duration of the corresponding operation (execution durations are given/measured by the user for each available pair of operation-type/processor-type or data-type/medium-type).
Both last windows File root.m4 and File P1.m4 show the automatically generated code, one code file (.m4) for each processor of the architecture graph. Actually, they are macro-codes independent from hardware components that must be macro-processed with the standard gm4 macro-processor. It replaces each macro-instruction by the corresponding source code contained in executive kernels and applications libraries (.m4x). These sources codes are dependent from the hardware components, and will be in turn compiled to obtain executable code.
Using the graphical user interface, the user may open as many algorithms and/or architectures as necessary. Through contextual menus, he may create, copy, cut, paste and connect objects (vertices and edges) inside a window, or between windows of the same type (algorithm or architecture). Then, after labelling (main) one of the algorithm windows and one of the architecture windows, by clicking the Adequation-menu he launches the distribution and scheduling optimization heuristics on this pair of main-labelled graphs, which displays its results in the timing window. This corresponds to the predicted real-time behaviour of the algorithm running on the architecture. Finally, by clicking the Code-generation-menu he launches the automatic generation of an optimized distributed macro-executive, which produces as much files as there are of processors. This macro-executive, independent of the processors and of the media, is directly derived from the result of the adequation. It will be macro-processed with gm4 using executive-kernels which are dependent of the processors and the media, in order to produce source codes. These codes will be compiled with the corresponding tools (several compilers or assemblers corresponding to the different types of processors and/or source languages), then they will be linked and loaded on the actual processors where the applications will ultimately run in real-time.