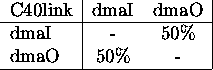Le problème d'optimisation consiste à choisir parmi toutes les
transformations réalisables à partir d'un couple (Graphe Algorithme, Graphe
architecture) celle qui respecte les contraintes temps-réel et minimise le
nombre de composants utilisés pour construire l'architecture.
Pour cela, on doit avoir caractérisé en termes de durée
l'architecture à un niveau suffisamment fin, ce qui permet de valuer le
graphe de l'algorithme par des durées d'exécution des calculs et des
communications en vue de faire des calculs de chemin critique pour
l'optimisation de la latence ou des calculs de boucle critique pour
l'optimisation de la cadence.
Ces problèmes d'optimisation étant NP-complets, on utilise une
heuristique ``itérative-gloutonne'' de distribution-ordonnancement, de
faible complexité ( nb processeurs  nb opérations).
nb opérations).
Pour la latence, elle consiste à faire progresser le long du graphe de l'algorithme valué, une coupe séparant les opérations déjà placées sur des processeurs de celles qui ne le sont pas encore. La progression se fait en respectant les précédences du graphe d'opérations. De toutes les opérations à distribuer sur la coupe et de tous les processeurs, on choisit la paire qui optimise une fonction de coût locale prenant en compte :
On peut aussi s'intéresser à d'autres critères d'optimisation :
Heuristique pour la latence
L'heuristique sélectionne globalement une transformation en étudiant étape par étape des transformations élémentaires locales
Transformation élémentaire :
distribution/ordonnancement d'une opération qui peut entraîner
distribution/ordonnancement d'opération(s) de communication avec choix
de route(s)
A chaque étape sélection selon une fonction de coût
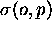 d'une opération o dans une liste d'opérations candidates
affectée un processeur p
d'une opération o dans une liste d'opérations candidates
affectée un processeur p
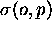 appelée schedule pressure est la différence entre
appelée schedule pressure est la différence entre
- schedule penalty augmentation du chemin
critique
- schedule flexibility marge :
différence date au plus tôt date au plus tard
La liste des candidats 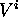 sont les opérations non encore distribuées-ordonnancées et dont les prédécesseurs ont tous été
distribués-ordonnancés
sont les opérations non encore distribuées-ordonnancées et dont les prédécesseurs ont tous été
distribués-ordonnancés
Elle conserve la fermeture transitive du graphe de l'algorithme
La paire (opération,processeur) sélectionnée à l'étape i est celle qui vérifie :
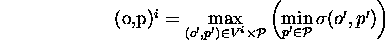
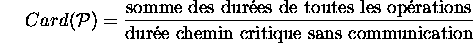
Si contrainte de latence satisfaite, diminuer le nombre de composants
Sinon modifier les contraintes distribution/ordonnancement
Sinon modifier l'algorithme
Heuristique pour la cadence
Caractérisation des performances temps réel
Chaque composant automate est caractérisé par une table
 durée d'exécution
(mesurée hors arbitrage)
durée d'exécution
(mesurée hors arbitrage)
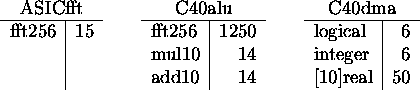
opérateur1  opérateur2
opérateur2  coefficient d'interférence
coefficient d'interférence
interférence = ralentissement opérateur1 lorsque opérateur2 actif
inactivité = attente de synchronisation